
5月30日(火) ~ 6月2日(金)に行われたAWS Summitに参加してきました。
日本で行われるAWSイベントの中では最も大きな規模です。
http://www.awssummit.tokyo/index.htmlwww.awssummit.tokyo
場所は品川プリンスホテルで行われました。

↑飛天の間の噴水にそびえるAWSロゴ
AWSさん、どんだけ凝ってるんですかw
今回、私は業務の合間にDay2の午前とDay3の午後に参加してきましたので、
以下にレポートを書いていきます。
- 5/31 (Day 2)
- 6/1 (Day 3)
- 参加した感想
5/31 (Day 2)
基調講演レポート

- 基調講演①
- 16分野のコンピテンシーというのがあるので、これに沿ってAWSの分野を学習していけばいいかも。
- Enterprise JAWS-UGというものもあるらしい。
- アップデートトピック①
- 日本準拠法を選択可能に
- 支払い通過を日本円で請求できるように
- サービスコンソールの完全日本語化を目指す。
- Digital/IT Transformationの流れが日本にもきている。
- Digital/IT Transformationの紹介:UFJの例
- ビジネス基盤を強化することについて
- 設定の素早さ+経営の俊敏さが要求される
- ビジネス基盤を強化することについて
- 基調講演②
- 画像認識を使ってルービックキューブをミリ秒で解く動画がとても面白かった。
- ↓例えばこんなの
- 画像認識を使ってルービックキューブをミリ秒で解く動画がとても面白かった。
- アップデートトピック②
- Lightsail 本日より東京で使用可能に。
- PostgreSQL Aurora
- オープンなデータベースが復旧してきていることは、確かに実感できる。
- Oracleに追いついてきた感。
- PostgreSQL AuroraのパフォーマンスはMAX2倍
- クラウド移行への流れ
- プロジェクト→ハイブリッド→クラウドファースト→全面移行
- Digital/IT Transformationの紹介:EPSONの例
- Oracleのラックで動いていたんだが、データベースが高トラフィックだった。
- これをどうにかしなきゃいけない。
- そこで選んだのがAurora。全面的にMySQLを採用。
- Oracleのラックで動いていたんだが、データベースが高トラフィックだった。
-
- 可用性の心配→Auroraは止まらないよね?→やってみないと分からない。
- 結果、運用工数0→DBAの作業を開発チームに移管可能に
- ライセンス費用0
- 障害0!すごい!
- Digital/IT Transformationの紹介:レコチョクの例
- VRの取り組みいいね。
- 配信方法や端末負荷、画質・音質の問題など課題はある。
- スマホ向けVR映像を横展開とか、VRライブ映像をお届けとか。
- 世界中に配信環境を提供するためにはどうすればいいのかとか。
- VRの取り組みいいね。
- 基調講演③
- ペタバイト規模のデータ移行にSnowball!
- 容量80TB * n
- ペタバイト規模のデータ移行にSnowball!
- IOT→クラウドがないと実現が難しい?
- 意味のあるIOTを実践→ホームセンターのGooDayもIOTやってる(すごいなーw)
- アップデートトピック③
- パリ、中国(地名忘れた)、ストックホルムにリージョンを追加予定。
- リージョンは物理的な拠点。
- Osaka Local Regionを解説予定
- 特定の顧客に限定したローカルリージョン
- パリ、中国(地名忘れた)、ストックホルムにリージョンを追加予定。
- AWSはセキュリティとコンプライアンスの要件を満たすインフラストラクチャー
- 医薬品・医療機器のコンプライアンス対応
- クラウドCoEのチームで事業部と連携することが、クラウド導入解決の近道でありイノベーションを推進するために不可欠。
6/1 (Day 3)
「AWSで実現するセキュリティ・オートメーション」レポート
- セキュリティオートメーションという言葉を聞いたことがあるか?→ない
- なぜクラウドを使わないかアンケート取った
- →一番の理由はセキュリティ
- なぜクラウドに移行したのかアンケート取った
- →一番の理由はセキュリティ
- セッションのポイント
- オートメーションは戦略策定の礎
- セキュリティ・オートメーションを前提に設計されたAWSサービス
- セキュリティ戦略基盤となるAWSクラウド環境
オートメーションは戦略策定の礎
- オートメーションは自動化のこと
- 例)セールスフォースオートメーション
- 営業プロセスの効率化→営業活動の革新(効率化の先にあるもの)
- 例)マーケティングオートメーション
- マーケティングの効率化→マーケティング活動の革新
- 例)セールスフォースオートメーション
- 「やること」と「やらないこと」を決められる = 戦略
- 多種多様なデータ集約→可視化と効果測定→分析による意思決定
- →この土台になっているのがオートメーション
セキュリティ・オートメーションを前提に設計されたAWSサービス
- 対策主体
- 対策対象
- 対策場所
- ガートナーの適応型セキュリティアーキテクチャ
- 予測・防御・対応・検知
- 防御
- →SG, NACL, WAF, CloudFront
- 検知
- →VPC flow logs, Auto Scaling
- 予測
- →AWS Config, Amazon Inspector
- 対応
- →AWS Lambda, Amazon SNS
- 監視
- →CloudWatch, CloudTrail
- IPブラックリストをAWS WAFに自動反映する仕組み(面白い!)
- →Lambdaで外部のブラックリストを取得して、WAFのIPセットを更新
- IPリストに反映されていない悪いIPを遮断する対策が必要
- →オートスケールによるトラフィック分散による問題の抑制(吸収)
- →スケーリングイベントの通知をAmazon SNSで
- →イベント通知をきっかけでLambdaを起動しセキュリティ評価を実行
- →Amazon InspectorのAPIをキックして、脆弱性診断
- →診断結果をSNSに通知→Lambda起動してNACL/SGのポートブロックによる端末隔離
- →VPC Flow Logsにブロックログを残す。→EC2インスタンスの状態をS3に保存する
- →CloudTrailにバックアップログ保存
セキュリティ戦略基盤となるAWSクラウド環境
- AWSインフラ全体のログ取得が可能
- →アクセスログ、S3のアクセス、API操作のログ
- →オンプレミスだと意外に大変だよね。AWSなら標準で提供されている。
- 可視化
- VPC Flow LogsとAmazon Elasticsearch Service/Kibanaによるセキュリティグループの可視化
- 分析
- Domain Generation Algorithms
- CloudFromtのログを見れば、ドメインが分かる。ここでマッチングさせる。
- AMLで正しいドメインの学習データとして食わせる。
- AMLの結果を見て、WAFルール更新なんてこともできる。
- AML起動はLambdaで。ログパーサーAML呼び出し
- リスク分析
- 脅威分析→異常検知、ヒューリスティック分析、脅威インテリジェンス
- 脆弱性分析→脆弱性スキャン、ベンチーマーク評価、
- 情報資産分析

- クラスメソッドさんのレポートもおすすめです。
「Amazon Aurora (MySQL-compatible edition) Deep Dive」レポート
Deep Dive
- データベースサービス
- AWSが一から作ったデータベースエンジン
- 一番の特徴はストレージ
- 一から作った
- SSDを利用したシームレスにスケールするストレージ
- 10GBから64TBまでシームレスに自動でスケールアップ
- 標準で高可用性を実現
- S3に高速にバックアップする仕組みを備えている。

- ストレージノードクラスタ
- Protection Group毎に6つのストレージノードを使用
- 各ログレコードはLog Sequence Numberを持っており、不足・重複しているレコードを判別可能
- 6つのストレージノードを使用
- ディスク障害検知と修復
- 2つのコピーに障害が起こっても、読み書きに影響はない
- 3つのコピーに障害が発生しても読み込みは可能。
- →なのでアベイラビリティゾーンが一つ落ちても大丈夫。
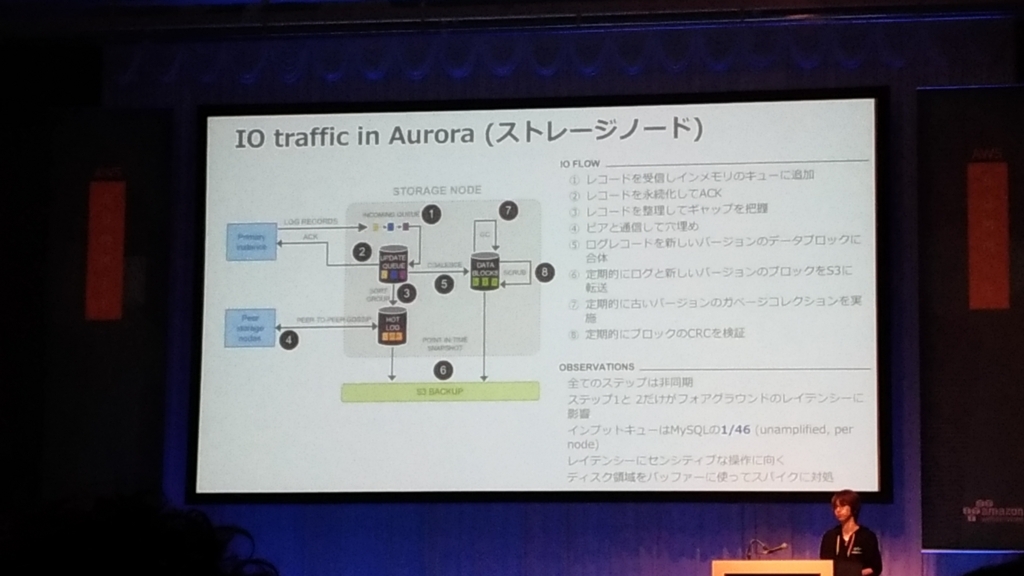
- IO traffic in Aurora(ストレージノード)
- 全てのステップは非同期
- スループットの影響が起きないように作られている。
- 6本のうち4本からストレージが帰ってくれば問題ない。(2本はあとで保管。)
- セキュリティ
- データの暗号化サポート
- SSLを利用したデータ通信の保護
- フェイルオーバーとリカバリ
- リードレプリカがある場合1分ほどでフェイルオーバー可能
- リードレプリカが存在しない場合10-15分
- Multi-AZ配置として別AZで起動可能
- 高速でより予測可能なフェイルオーバー時間
- クラッシュリカバリの速度が3病から20病で終わるように設計
- →Auroraがやるんじゃなくてストレージノードが判別してやっているから早い。
- Auroraのフェイルオーバータイムの内訳は、一瞬で終わるのが30%。
- Streaming backupとPITR
- ストレージに書き込まれた瞬間からS3に継続的にかかれていく仕組み。
- AuroraはそのままログとしてS3に書き込まれる。
- 何があってもパフォーマンステストをいつしてもBackupを含んだペナルティの性能になっている。
- 任意の位置で復元可能。
- 各セグメントは定期的なSnapshotは並列で行われ、redo logはストリームで継続
- バックアップのためにS3に送られる。パフォーマンスや可用性に対する影響はなし
- Writer / Readerノートの識別
- innodb_read_onlyモードでマウントされている。
- SHOW GLOBAL VARIABLES LIKE 'innodb_readonly'
- SQLによるフェイルオーバーのテスト
- SQLによりノード・ディスク・ネットワーク障害をシミュレーション可能
- ディスク障害、ディスクコンジェスションをシミュレーションが可能
- →これらSQLはAuroraのみに実装されているクエリ
- Aurora Driver
- MariaDB Connector/JにFast failover Auto node discoveryが実装されているので、このDriverを使ってみてほしいとのこと。
- Fail Over時間が短縮されるよ。
- MariaDB Connector/JにFast failover Auto node discoveryが実装されているので、このDriverを使ってみてほしいとのこと。
- パフォーマンスTips
- Auroraのパフォーマンスは圧倒的
- チューニング設計
- MySQLのチューニング戦略がそのまま適用できる。
- Auroraはマシンリソースを最大限使うような設計になっている。
- CPU、スループットなど、CloudWatchで監視して確認してほしい。
- まずはデフォルトのパラメータグループ使用を推奨?。
- →その後、適切なインスタンスタイプを選択することが大切。
- トランザクションで大量の更新や削除を行ったり、大量データのシーケンシャルリードを行う場合、区切れる単位でSQLを分割して並列で投げてくれると、性能が上がりやすい。
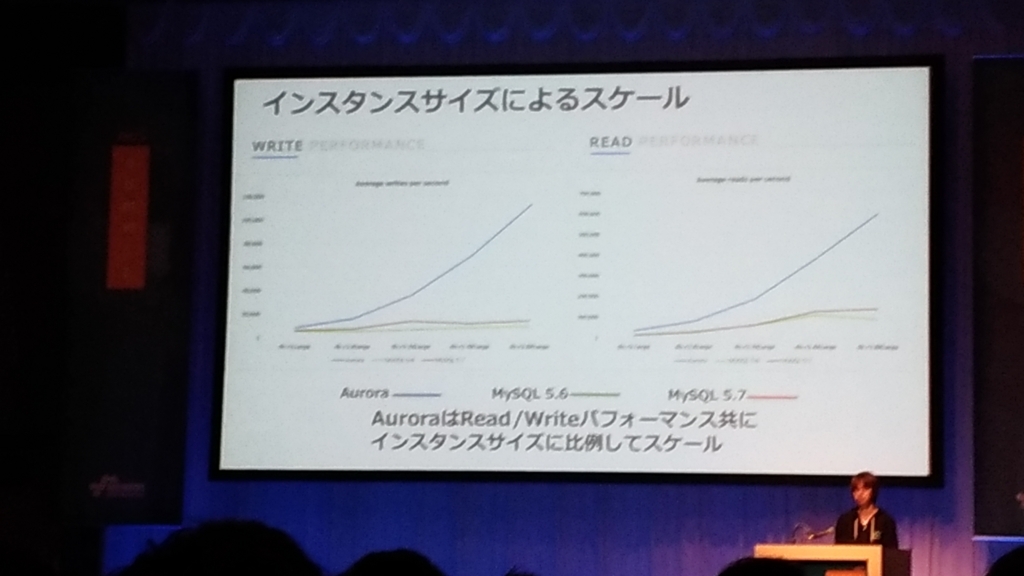
- スループット最大限に出すのがAuroraの最大の特徴
- 新しいメトリクス画面、メトリクススキーマ
- メトリクススキーマ見るのすごく楽しそうだな!
- 拡張モニタリング
- Elastic Service連携も可能
- Auroraへの移行は?
- InnoDBのみサポートしているので、マイグレーション時に自動でコンバートされるが、手動で対応ストレージエンジンに変換しておくのがよい。
- RDSからの移行は、
- Aurora Read Replicaを自動生成する機能があるので、最新のデータによる移行が可能。
- Percona Xtrabackupを利用してAuroraへ移行可能
- mysqldumpと比較したテストで20倍高速に移行可能
改善を行ってきた機能(前回のサミットから追加された機能の一部を紹介)
- Reader Endpoint
- →ロードバランサみたいなエンドポイントがあって、ラウンドロビンで振り分けられる。
- →Readerが一瞬でも消えた場合はフェイルバックが起こり、Writerを指す場合がある。
- IAM Authentication Integration
- Amazon Auroraへログインするための認証にIAMが利用可能に
- →credentialを配布する必要がないので、開発だけアクセスできる本番だけアクセスできるような使い方が可能。
- IAMポリシーで矯正が可能?
- Lambda Function Integration
- ストアド・プロシージャとして実行
- Load Data From S3
- S3バケットに保存されたデータを直接Auroraにインポート可能
- テキスト形式、XML形式
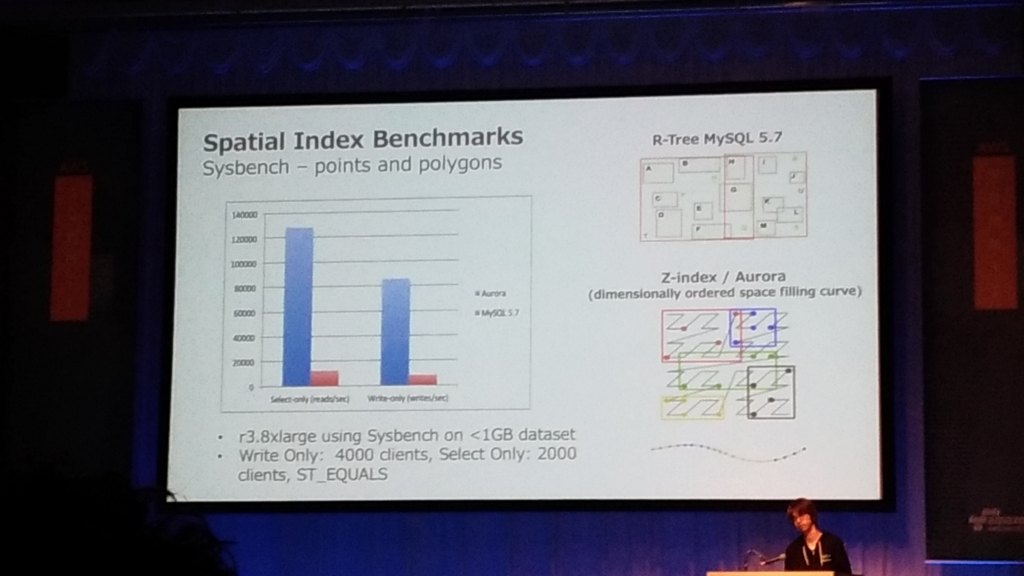
- 空間インデックスサポート
- Auroraに入れる時に性能の改善が行われているので、ベンチマークで2倍の性能差が出てる。
- インデックスの持ち方を変えたことで、性能向上。
- 同じメソッド、関数を持っているけど内部的にはインデックスの持ち方が変わっている。
- 監査の機能
- Aurora native audit supportは15%程度の性能ダウンでいける。
- ログファイルに出力するところを、パラレルに書き込むできるようにすることで、性能を向上させた。
- →mariadb server_audit pluginとの比較です。
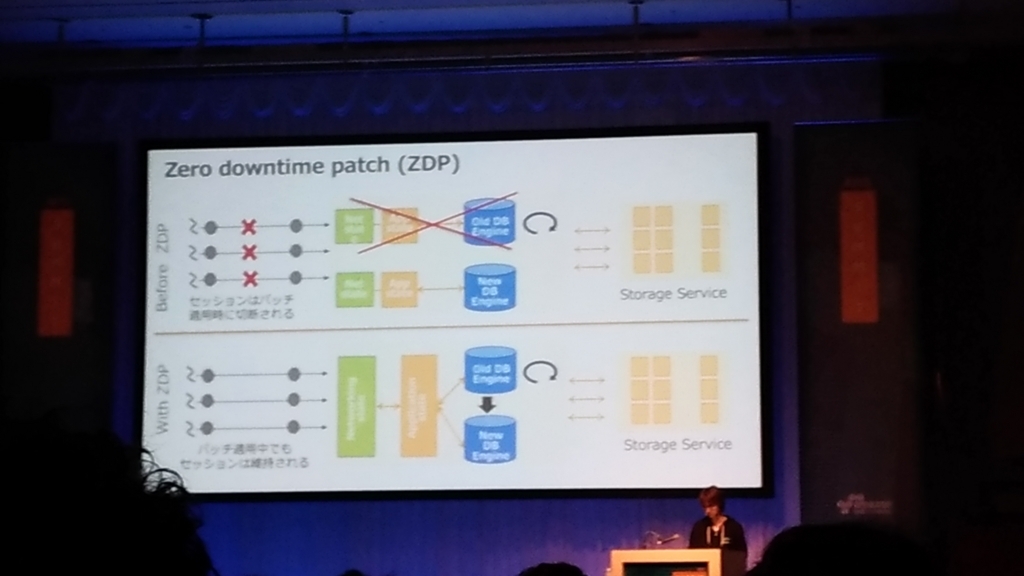
- Zero downtime patch(ZDP)
- コネクションを切断することなくオンラインでパッチを適用できる
- 5秒程度スループットの低下が起こるが、接続を維持したままパッチを適用可能に。
- ベストエフォートなので、この機能を期待してアプリを作るのはやめたほうがいい。
- 性能面
- Cached read performanceの改善
- →性能はどんどん挙がっている。
- Insert Performance→地道なパフォーマンス改善を続けている。
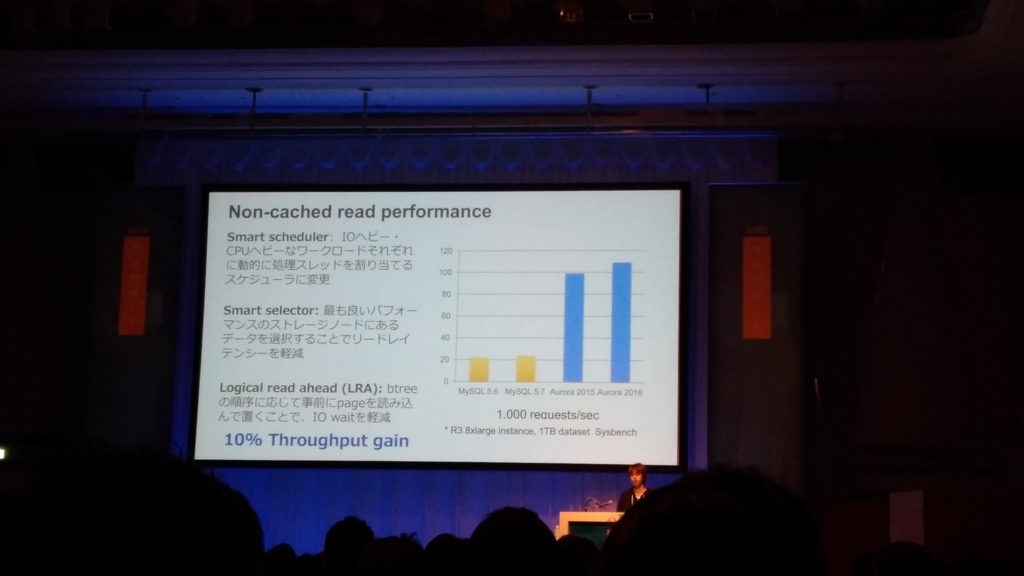
- Fasted Index build
- Lab Modeがある。
- FAST DDL
- add columnが1秒もかからない処理になる
- FAST DDL
さらなる改善に向けて
- データベースバックトラック
- オペミスの内容を一瞬で特定の状態に戻す機能
- データは残っているんだけど、シーケンスNo的なものを巻き戻すことで、戻す
- 超高速に巻き戻す
- →バックアップから別のクラスを立ち上げるのではないので、リカバリが早い。
- Databse cloning
- ストレージコストを増やすことなくデータベースのコピーを作成
- 1分か2分くらいでCloningできる。
- その↑にインスタンスを立てればいい。
- 料金はコピーしただけだとストレージ料金はかからない。
- cloneに書きこんだ分の料金はかかるかも?。
- Auroraは高いクエリ実行並列度、データサイズが大きい環境で性能を発揮
- コネクション数やテーブル数が多い環境で優位
- AuroraとRDSでパフォーマンステストをして、試してほしい。
- データの堅牢性はAuroraに軍配。
「【AWS Tech 再演】AWS のコンテナ管理入門(Amazon EC2 Container Service)」レポート
なぜコンテナなのか
- DevOpsのために再発見された
- 開発に専念したい→インフラの運用管理を効率化した
- 可搬性→不変なイメージ
- イメージを本番環境にそのままリリースできるのっていいよね。
- 柔軟性、速度
- ベスト・プラクティス
- アプリをコンテナに適応させる(12 factor apps)
- 複雑さを避ける→シンプルに保つ
- タスクに集中する
- タスク = ジョブの単位
- そこで登場する課題:クラスタ管理
- 1台のサーバ上でコンテナを扱うのは簡単
- 複数ホスト上でのコンテナ管理は非常に難しい
- アプリケーションの開発に専念したいはず
Amazon EC2 Container Service 概要
- メリット
- 簡単に、どんなスケールのクラスタも管理できる
- 状態管理、操作、監視、スケーラブル
- 柔軟なコンテナの配置
- アプリケーション、バッチジョブ、複数のスケジューラ
- 他のAWSサービとの連携がデザインされている
- 拡張性の高さ -> 分かりやすいAPI
- アーキテクチャ
- Taskはコンテナ
- EC2にエージェントを入れる。

- コンテナ
- ECS AGENT
- MANAGER
- CLUSTERのリソースとTASKの状態を管理
- 変化を追跡
- TASK DEFINITIONS
- コンテナ情報とボリューム情報に分割
- Task
- コンテナ実行の1単位
- 関連するコンテナでグループされる
- スケジューラ
- Run Task←バッチに最適
- Service←Web/APIに最適
クラスタに対してマネージャーを介してスケジューラからタスク定義的な
- クラスメソッドさんのレポートもおすすめです。
【レポート】AWS Summit Tokyo 2017:AWS のコンテナ管理入門(Amazon EC2 Conatainer Service) #AWSSummit | DevelopersIO
「【AWS Tech 再演】Machine Learning on AWS」レポート
- 解決したいビジネス課題から出発したほうがいい。
- ツールなので、それ自体を使うことが目的ではない。
- もっとシンプルで簡単なやり方のほうがいいということはよくある。
- それでも上手くいかないケースで活用するべき
- 大量のデータ→学習アルゴリズム→機械学習モデル
- 大量の良質なデータでモデルの精度が向上
- →(良質なデータが)継続的に手に入るかどうかが重要
- 判断や予測を自動化することが可能
- →自動化する価値のあるクリティカルな予測か?
- 大規模に展開するほどコストが下がる
- →費用対効果に見合うか?
- 機械学習に向いている分野
- レコメンド(これも買っています的な)
- 異常検知
- 画像認識
- クラスタリング(マーケティングの)
- Hardware
- DeepLearningに最適なインスタンス(P2インスタンス)
- green glass
- AI Engines
- インストールがものすごくめんどくさい
- AMIイメージで簡単に利用できる
- MXNetを全面的にサポート
- →スケーラビリティに優れている。
- AI Platform
- AML マネージドサービス
- EMR
- AI Service
- アプリケーションサービス
- Right tools for the job
- Managed services first
- ゴールを明確にする
- モデル
- トレーニング
- 予測
- クラスメソッドさんのレポートもおすすめです。
【レポート】AWS Summit Tokyo 2017: Machine Learning on AWS #AWSSummit | DevelopersIO
参加した感想
私は今回AWS Summitに参加するのは初めてだったのですが、
その圧倒的なイベント規模に驚かされるばかりでした。
ユーザイベント規模ではなし得ないことばかりです。
AWSがお金持っているということなんでしょうけどw
タイミングがいいのか悪いのか夏日並みの気温だったので、
品川プリンスホテルまでの道中が暑いこと・・
会場の人の多さにも圧倒され気疲れが大きかったです。
この雰囲気の中1日中勉強のためにTechトラックを見るのは
かなり大変なんじゃないでしょうか。幸いなことに1トラック40分なので
集中力は持続できると思いますが。
私は今回Day2の午前中とDay3の午後のみ参加したので、
丸一日いたら普段の業務よりしんどかったんじゃないかとw
もちろん、Techトラックで勉強した収穫は大きいので、
参加できたことには大きな意味がありました。
ランチが出る無料の大規模イベントがあるらしい(It's AWS Summit 2017 Tokyo!)

カツサンドうまかったです。ありがとうございます。
認定者ラウンジで傘を頂きました。ありがとうございます。

もったいなくて使えないですわ・・
一時の癒やし:品川プリンスホテルの日本庭園

来年も日本庭園を拝めますように・・
晩御飯:一日分の野菜が採れるカレー

一日分の野菜って思った以上に量が多いw
栄養バランスを取るって大変ですね・・
AWSおみくじ(by クラスメソッド様)

Athena使うぜ!うひょー!
以上、レポート&感想でした!
参加した皆さん、お疲れ様でした!